|
I am a PhD student (2018.09-) in the State Key Laboratory of Software Development Environment (SKLSDE), SCSE at Beihang University,
supervised by Prof. Wei Li
and Prof. Xianglong Liu.
I obtained my BSc degree in Computer Science and Engineering (Summa Cum Laude) from Beihang University in 2018.
CV / Github / Linkedin / Google Scholar / |
 |
|
In my Ph.D. study, I devote myself to Trustworthy AI research and mainly focus on the physical adversarial examples generation, now I try to transfer to investigate the adversarial defense works in the physical world. I hold the review that physical adversarial attacks and defenses can powerfully promote the development of secure and robust artificial intelligence, leading to a healthier future society. Our previous works such as bias-based universal adversarial patch attack and dual attention suppression attack have achieved some results and draw some interesting conclusions. Now my research focus is mainly on:
|
[2021.08.21] One co-authored paper for scene text recognition is accepted by Elsevier JVCI. [2021.08.12] One paper for deepfake detection is accepted by ACM MM 2021 workshop: Adversarial Learning for Multimedia. [2021.07.23] One co-authored paper for object detection is accepted by ICCV 2021. [2021.05] I am selected in Doctoral Consortium IJCAI 2021 (7 people from Mainland China). [2021.03] One paper accepted by CVPR 2021 (Oral). [2020.12] Our open-source platform 重明 has been awarded the 首届OpenI启智社区优秀开源项目 (First OpenI Excellent Open Source Project). |
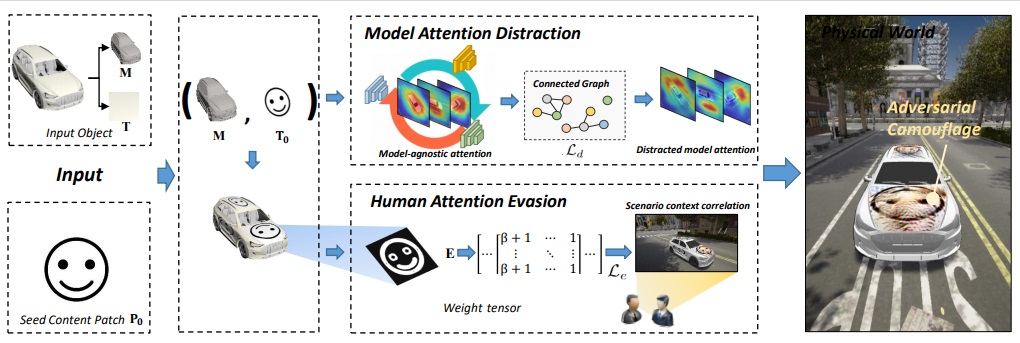 |
We propose the Dual Attention Suppression (DAS) attack to generate visually-natural physical adversarial camouflages with strong transferability by suppressing both model and human attention. |
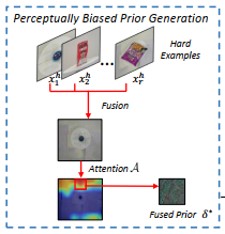 |
We propose a bias-based framework to generate class-agnostic universal adversarial patches with strong generalization ability, which exploits both the perceptual and semantic bias of models. |
 |
In this paper, we proposes a sequential alignment attention model to enhance the alignment between input images and output character sequences. |
 |
We present a High-quality X-ray (HiXray) security inspection image dataset and the Lateral Inhibition Module (LIM). |
 |
|
 |
|
 |
重明 is an open-source platform to evaluate model robustness and safety towards noises (e.g., adversarial examples, corruptions, etc.). The name is taken from the Chinese myth 重明鸟, which has strong power, could fight against beasts and avoid disasters. We hope our platform could improve the robustness of deep learning systems and help them to avoid safety-related problems. 重明 has been awarded the 首届OpenI启智社区优秀开源项目 (First OpenI Excellent Open Source Project). |
[2021.06] Beihang University Excellent Academic Paper Award. [2020.10] Beihang University First Prize Scholarship. [2020.09] China National Scholarship (Top2%). [2020.09] Beihang University Merit Student. [2019.10] Beihang University First Prize Scholarship. [2018.09] Beihang University Outstanding Freshman Scholarship (1/12). [2018.06] Outstanding Graduates of Beijing Province. |
|
|